


Longest Prefix Matching for IP Routing
An implementation of Longest Prefix Matching, for IP Routing in Rust using Binary Trie Data Structure

Previously I worked on IP Routing using Exact Matching using a Hash-Based data structure. This method required the exact network address specified for each destination IP. While this approach offers speed, it comes with certain limitations.
If you want to learn more about IP Routing check out my previous newsletter. Also, leave a like and comment on the post. Your feedback will help me improve my writing.
Longest Prefix Matching
Longest Prefix Matching (LPM) is a flexible approach. Unlike Hash-Based exact matching, LPM allows matching the longest prefix of the destination IP.

Explaining the above example, the router has two network addresses 192.168.1.0/24 and 192.168.1.0/28. If the packet with destination IP 192.168.1.33 has to be routed the router matches the longest prefix that is available, in this case to the next hop pointed to by 192.168.1.0/28 instead of 192.168.1.0/24.
Binary Trie
The Binary Trie data are composed of nodes and 2 children. The children represent 0 (left child) or 1 (right child).

Before we step into the implementation of a routing table based on Trie, let us understand LPM with a simple example.
Let’s say we have three binary values 1011, 0010, and 1001 (we can represent IP address in bits as well). These values can be represented as a trie as described in the figure below.

For a detailed explanation on Trie and how it can used for LPM, check the link. I found it very useful for my implementation.
Implementation
The implementation starts by defining the trie data structure. It has two children (0 or 1) and parameters describing the end of a specific network address and the route value.

We need two methods namely, an insert() method that inserts the network routes to the trie and a search() method that is used to find the Longest Prefix Matching route for a particular destination IP.
The insert() method takes the network address and the subnet mask as arguments. For each bit in the octet, it adds a node. At the end of the subnet mask, the added node is marked with end_node = true and the value (route information) is updated.
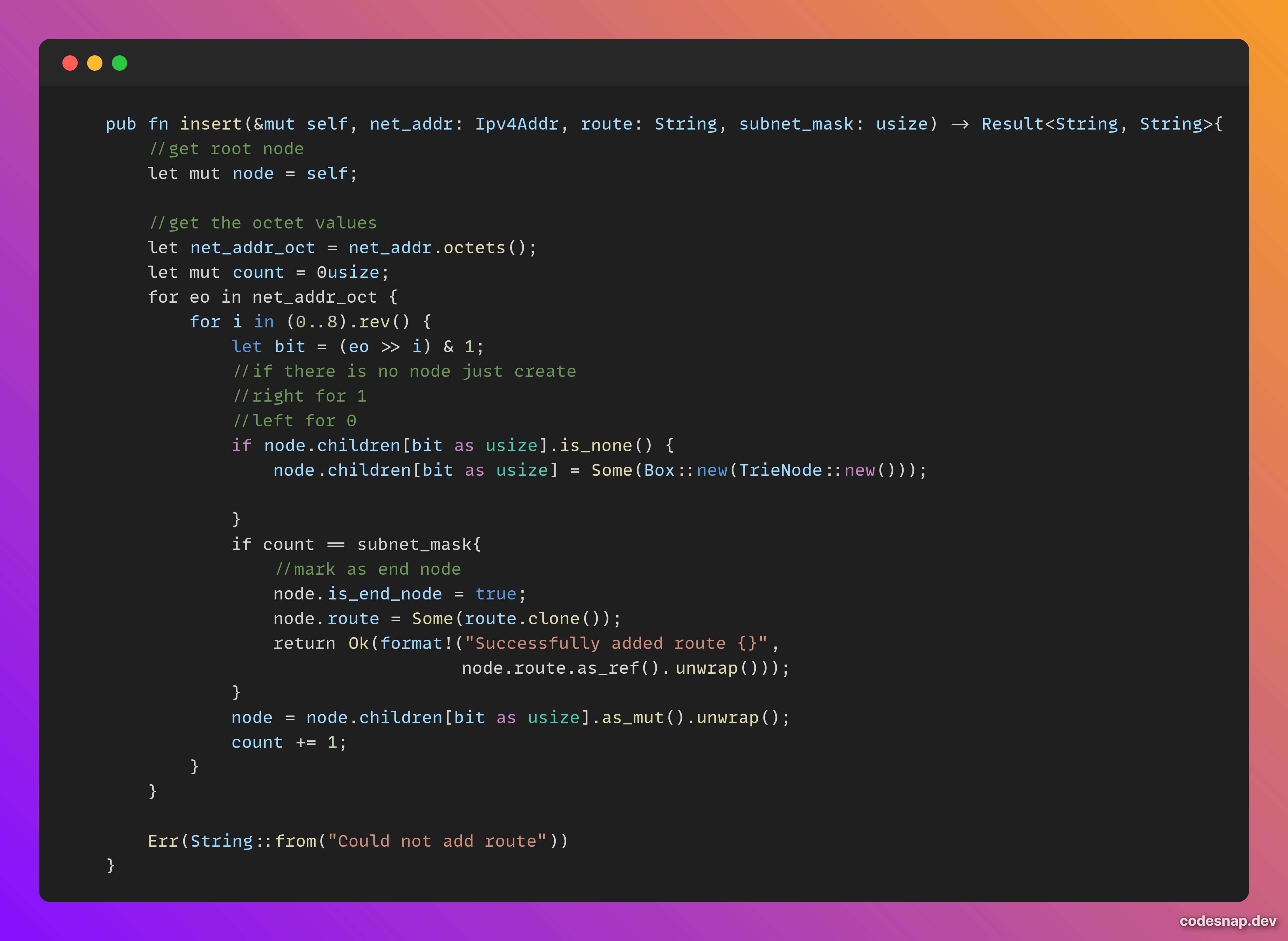
The search() method takes the destination IP address and searches for the longest prefix match on the trie. It keeps track of the last_route that was available and returns it if there is no perfect match.

The driver code is shown below. From the results, we can see that although there are two network addresses (192.168.0.0/24 and 192.168.0.0/28) that the destination IP 192.168.0.33 can be a part it routes the destination IP to en03 (which belongs to 192.168.0.0/28).

The trie binary data structure is popularly used for prefix matching. Not only in routing tables but also in search engines. Although they are very efficient with prefix matching the memory access is very large. Well, isn’t Software Engineering all about tradeoffs?
Checkout the entire source code: LpmUsingTrie
Follow me on Linkedin: anvayabn
If you like the post, please subscribe and support.